在PostgreSQL自定义一个“优雅”的type
是的,又是我,不要脸的又来混经验了。我们知道PostgreSQL是一个高度可扩展的数据库,这次我聊聊如何在PostgreSQL里创建一个优雅的type,如何理解优雅?大概就是不仅仅是type本身,其它相关的“服务”都得跟上,要像数据库自带的type一样想怎么用怎么用。
好的,我们开始。
1. CREATE TYPE
PostgreSQL能够被扩展成支持新的数据类型。这一节我们先说说如何定义新的基本类型,这里的type是被定义在SQL语言层面之下的数据类型。创建一种新的基本类型要求使用低层语言(通常是 C)实现在该类型上操作的函数。
例子来自于源代码src/tutorial目录下的complex.sql和complex.c。运行这些例子的指令可以在该目录的README文件中找到。
CREATE TYPE的语法在这里:http://www.postgres.cn/docs/9.5/sql-createtype.html
在PostgreSQL中,一种用户定义的类型必须总是具有输入和输出函数。这些函数决定该类型如何出现在字符串中(用于用户输入或者对用户的输出)以及如何在内存中组织该类型.
关于以上提到的这些,我先不要脸的画一个图吧:
outside(screen) inside(disk file)
| -------------------------> |
| complex_in |
| |
| |
| <------------------------- |
| complex_out |比如我们要创建一个复数类型complex,它的C语言描述如下:
typedef struct Complex {
double x;
double y;
} Complex;在用C语言实现时我们将需要让它成为一种传引用类型,因为它没办法放到一个单一的Datum值中(因为Datum里面只能放单一的基本数据类型)。
接着为美观易懂起见,我们选择字符串形式的"(x,y)作为该类型的外部字符串表达"。
也就是说,我们用"(x,y)"表示一个complex,并且在使用时我们这样书写,在查询时,数据库返回的也是这样的字符串。
我们写一个简单的输入函数吧:
Datum
complex_in(PG_FUNCTION_ARGS)
{
char *str = PG_GETARG_CSTRING(0);
double x,
y;
Complex *result;
if (sscanf(str, " ( %lf , %lf )", &x, &y) != 2)
ereport(ERROR,
(errcode(ERRCODE_INVALID_TEXT_REPRESENTATION),
errmsg("invalid input syntax for complex: \"%s\"",
str)));
result = (Complex *) palloc(sizeof(Complex));
result->x = x;
result->y = y;
PG_RETURN_POINTER(result);
}再来一个输出函数
PG_FUNCTION_INFO_V1(complex_out);
Datum
complex_out(PG_FUNCTION_ARGS)
{
Complex *complex = (Complex *) PG_GETARG_POINTER(0);
char *result;
result = psprintf("(%g,%g)", complex->x, complex->y);
PG_RETURN_CSTRING(result);
}函数写完了,也编译成动态库了(细节可以看看我之前的文章)。我们的数据库怎么知道去调用这些函数呢?
我们在SQL中这样定义函数(filename就是你的文件路径了):
CREATE FUNCTION complex_in(cstring)
RETURNS complex
AS 'filename'
LANGUAGE C IMMUTABLE STRICT;
CREATE FUNCTION complex_out(complex)
RETURNS cstring
AS 'filename'
LANGUAGE C IMMUTABLE STRICT;
CREATE FUNCTION complex_recv(internal)
RETURNS complex
AS 'filename'
LANGUAGE C IMMUTABLE STRICT;
CREATE FUNCTION complex_send(complex)
RETURNS bytea
AS 'filename'
LANGUAGE C IMMUTABLE STRICT;可选地,一种用户定义的类型可以提供二进制输入和输出函数。二进制 I/O 通常比文本 I/O 更快但是可移植性更差。与文本 I/O 一样,定义准确的外部二进制表达是你需要负责的工作。大部分的内建数据类型都尝试提供一种不依赖机器的二进制表达。
最后,我们可以提供该数据类型的完整定义:
CREATE TYPE complex (
internallength = 16,
input = complex_in,
output = complex_out,
receive = complex_recv,
send = complex_send,
alignment = double
);
到这里你应该在疑惑输入和输出函数是如何能被声明为具有新类型的结果或参数的?因为必须在创建新类型之前创建这两个函数。这个问题的答案是,新类型应该首先被定义为一种shell type, 它是一种占位符类型,除了名称和拥有者之外它没有其他属性。这可以 通过不带额外参数的命令CREATE TYPE name做到。然后用 C 写的 I/O 函数可以 被定义为引用这种 shell type。最后,用带有完整定义的 CREATE TYPE把该 shell type 替换为一个完全的、合法的类型定义,之后新类型就可以正常使用了
这样以后,某张系统表里就有新内容了。也就是说,你的type”注册“好了。
我们已经有了Complex这个数据类型,一旦数据类型存在,我们就能够声明额外的函数来提供在该数据类型上有用的操作。不然这个数据实际上就是一个空架子而已,还有一些聚集函数也没有支持。没办法进一步的使用。因此,有必要为它创建一些聚集函数和操作符。
本来是想先介绍操作符的,为行文连贯起见,我先讲讲创建聚集函数吧。
2. CREATE AGGREGATE
先放官方文档:http://www.postgres.cn/docs/9.4/xaggr.html
http://www.postgres.cn/docs/9.4/sql-createaggregate.html
以我个人的开发经验的话,一般写聚集函数会写成下面这个形式:
CREATE AGGREGATE xxx (complex)
(
sfunc = xxx_trans,
stype = internal,
finalfunc = xxx_final,
combinefunc = xxx_trans_merge,
serialfunc = xxx_serialize,
deserialfunc = xxx_deserialize,
parallel = SAFE
);我还是以聚集函数avg()为例来讲解吧。例如你执行"SELECT avg(a) FROM some_table;",
你求和要依次遍历每一个a吧?这里的sfunc(状态转移函数)就是做遍历操作的(数据库对每行都会调用一次sfunc,因此你的sfunc只要写针对一行的操作);
把每个a的值和遍历的值的个数要记下来吧?存这个你得弄个结构体啥的吧?这个stype就是指定这个变量类型的;
把所有的行都遍历完了我们要把总和除以行数才能得到结果吧?finalfunc()就是做这个事情的,它在遍历之后做最终处理。对这个finalfunc我多说一句,如果你写的聚集函数类似于sum()这种,遍历完我就可以得到结果,那么我们就可以不定义finalfunc,但是你的stype必须就是你的函数返回值类型。
有了这三个函数,聚集函数就可以跑起来了。剩下的几个函数和参数是PostgreSQL在9.6时为支持并行查询时加入的。还是以执行"SELECT avg(a) FROM some_table;"为例:
并行查询要支持并行聚集的话,那么我必须要能把每个并行的process的结果合并在一起吧?怎么办?上combinefunc函数吧,它用来合并两个"中间状态";
上面说的我要合并各个process间的数据,那么要保证各个process间可以传递数据吧?所以要序列化和反序列化,所以就要写serialfunc和deserialfunc;
最后你写了以上这些函数,支持了并行,那么就设置parallel为SAFE,让数据库知道你支持了parallel,否则数据库默认对你这个聚集函数不并行处理。
聚集函数差不多就是这些,聚集函数是可以重载的,然后上面这些函数都写成针对complex的实现,数据库就会自己去调用。具体实现细节不想讲了,不是本篇的主题(可能会另开一篇细讲服务端编程)。
好的。现在再说operator。
3. CREATE OPERATOR
语法在这里:
http://www.postgres.cn/docs/9.5/sql-createoperator.html
http://www.postgres.cn/docs/9.5/xoper.html
CREATE OPERATOR name (
PROCEDURE = function_name
[, LEFTARG = left_type ] [, RIGHTARG = right_type ]
[, COMMUTATOR = com_op ] [, NEGATOR = neg_op ]
[, RESTRICT = res_proc ] [, JOIN = join_proc ]
[, HASHES ] [, MERGES ]
)粗略地说,对于一个我们想要创建的操作符,我们要指定:
操作符名字(name),
一个处理函数(PROCEDURE),
指定它是几元操作符(LEFTARG,RIGHTARG),
操作符的交换子(如果对于所有可能输入的 x、y 值, (x A y) 等于 (y B x),我们可以说操作符 A 和 B 互为交换子。)(COMMUTATOR),
求反器(neg_op),
那么对于上面提到的complex类型,我们增加一个"+"操作符吧。
CREATE FUNCTION complex_add(complex, complex)
RETURNS complex
AS 'filename', 'complex_add'
LANGUAGE C IMMUTABLE STRICT;
CREATE OPERATOR + (
leftarg = complex,
rightarg = complex,
procedure = complex_add,
commutator = +
);4. CREATE OPERATOR CLASS
有了操作符,我们可以对数据进行一些必要的操作了。我们玩着玩着,数据量就大了,这时候我们很当然的想我们需要一个索引啊。然而一个索引方法的例程并不直接了解它将要操作的数据类型。而是由一个 操作符类标识索引方法。
那么好吧,我们创建一个操作符类,为了索引。我们知道,在创建索引的时候我们是要选择索引类型的,比如B树索引,gin索引,gist索引等等。
语法如下:
CREATE OPERATOR CLASS name [ DEFAULT ] FOR TYPE data_type
USING index_method [ FAMILY family_name ] AS
{ OPERATOR strategy_number operator_name [ ( op_type, op_type ) ] [ FOR SEARCH | FOR ORDER BY sort_family_name ]
| FUNCTION support_number [ ( op_type [ , op_type ] ) ] function_name ( argument_type [, ...] )
| STORAGE storage_type
} [, ... ]我们可以从语法里看到:这个操作符类是针对某一个type指定为某种index_method时服务的,也就是说我比如这次为complex指定了b-tree索引的操作符类,那么我要是想用complex类型的hash索引,对不起我们得为hash索引再建立一个操作符类
下面我依次来说明下CREATE OPERATOR CLASS语法中"{"和"}"之间的文字的意思。
首先对于OPERATOR:
OPERATOR strategy_number operator_name [ ( op_type, op_type ) ] [ FOR SEARCH | FOR ORDER BY sort_family_name ]与一个操作符类关联的操作符通过"策略号"(strategy_number)标识,它被用来标识每个操作符在其操作符类中的语义。例如,B-树在键上施行了一种严格的顺序(较小到较大),因此"小于"和"大于等于" 这样的操作符就是 B-树所感兴趣的。因为PostgreSQL允许用户定义操作符, PostgreSQL不能看着一个操作符(如<和>=)的名字并且说出它是哪一种比较。
取而代之的是,索引方法定义了一个"策略"集合, 它们可以被看成是广义的操作符。每一个操作符类会说明对于一种特定 的数据类型究竟是哪个实际的操作符对应于每一种策略以及该索引语义的解释。
我们可以在代码里看到这些策略号:
src/include/access/stratnum.h我们先看下b-tree的策略号。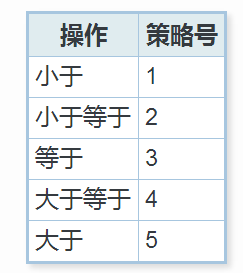
假如我们给complex写了很多操作符,其中我们写了个"@<"这个操作符,我们也不知道这个操作符是干什么鬼的,但是我们知道"a @< b"表达的"a小于b",那么我们就知道他针对b-tree索引的策略号是1,那我们这么写:
OPERATOR 1 @<(complex, complex)下面再来说FUNCTION:
我们说OPERATOR有strategy_number,那么对于FUNCTION,他类似的也有support_number:

也就是说你得实现这些函数,索引才能正常工作:
FUNCTION 1 complex_abs_cmp(complex, complex)最后,storage_type是实际存储在索引中的数据类型。通常这和列数据类型相同,但是有些索引方法(当前有 GiST 、GIN 和 BRIN)允许它们不同。 除非索引方法允许使用不同的类型,STORAGE子句必须被省略。那我们也省略吧。
有关strategy_number和support_number看这里:
http://www.postgres.cn/docs/9.5/xindex.html
其实到这里,我也可以结束本文了,因为真的差不多写完了。然而人还是有强迫症的。奈何官方手册上还有个操作符族。老实说,我目前的应用场景还没遇到过。算了还是写上吧,感觉终究躲不过的。
(以下抄的官方手册)
到目前为止,我们暗地里假设一个操作符类只处理一种数据类型。虽然在 一个特定的索引列中必定只有一种数据类型,但是把被索引列与一种不同 数据类型的值比较的索引操作通常也很有用。还有,如果与一种操作符类 相关的扩数据类型操作符有用,通常情况是其他数据类型也有其自身相关 的操作符类。在相关的类之间建立起明确的联系会很有用,因为这可以帮 助规划器进行 SQL 查询优化(尤其是对于 B-树操作符类,因为规划器包 含了大量有关如何使用它们的知识)。
为了处理这些需求,PostgreSQL 使用了操作符族的概念。 一个操作符族包含一个或者多个操作符类,并且也能包含属于该族整体而 不属于该族中任何单一类的可索引操作符和相应的支持函数。我们说这样的 操作符和函数是"松散地"存在于该族中,而不是被绑定在一个 特定的类中。通常每个操作符类包含单一数据类型的操作符,而跨数据类型 操作符则松散地存在于操作符族中。
(以上抄的官方手册)
看不懂的话上例子。
CREATE OPERATOR FAMILY integer_ops USING btree;
CREATE OPERATOR CLASS int8_ops
DEFAULT FOR TYPE int8 USING btree FAMILY integer_ops AS
-- 标准 int8 比较
OPERATOR 1 < ,
OPERATOR 2 <= ,
OPERATOR 3 = ,
OPERATOR 4 >= ,
OPERATOR 5 > ,
FUNCTION 1 btint8cmp(int8, int8) ,
FUNCTION 2 btint8sortsupport(internal) ;
CREATE OPERATOR CLASS int4_ops
DEFAULT FOR TYPE int4 USING btree FAMILY integer_ops AS
-- 标准 int4 比较
OPERATOR 1 < ,
OPERATOR 2 <= ,
OPERATOR 3 = ,
OPERATOR 4 >= ,
OPERATOR 5 > ,
FUNCTION 1 btint4cmp(int4, int4) ,
FUNCTION 2 btint4sortsupport(internal) ;比如我们有以上int4和int8的操作符类,以及他们共同属于一个操作符族。
我们知道,虽然int4和int8不是同一种数据类型,但是在一般我们认为安全的情况下,我们还是经常会把他们之间做比较的,比如大于小于相等之类的。对于他们比较的操作,我们扩展重载几个操作符就好了,让int4和int8可以相加之类的。但是他们却不能在索引时被使用,于是这时候我们用上了操作符族:
我们把int4和int8放在一个操作符族下,然后:
ALTER OPERATOR FAMILY integer_ops USING btree ADD
-- 跨类型比较 int8 vs int4
OPERATOR 1 < (int8, int4) ,
OPERATOR 2 <= (int8, int4) ,
OPERATOR 3 = (int8, int4) ,
OPERATOR 4 >= (int8, int4) ,
OPERATOR 5 > (int8, int4) ,
FUNCTION 1 btint84cmp(int8, int4) ,
-- 跨类型比较 int4 vs int8
OPERATOR 1 < (int4, int8) ,
OPERATOR 2 <= (int4, int8) ,
OPERATOR 3 = (int4, int8) ,
OPERATOR 4 >= (int4, int8) ,
OPERATOR 5 > (int4, int8) ,
FUNCTION 1 btint48cmp(int4, int8) ,这样我们就可以在索引里面支持这样的比较了。
这篇就是这样了。下回要不就谢谢服务端编程,或者再开写postgreSQL的executor的执行源码分析。
朋友们,下篇文章见吧~
欢迎点赞。。。
智能推荐
注意!
本站转载的文章为个人学习借鉴使用,本站对版权不负任何法律责任。如果侵犯了您的隐私权益,请联系我们删除。